Today we're learning about Clickhouse, which is a column-oriented DBMS that's optimized for speed and performance.
primary.idx
- What is an Engine, and DBMS 101
- Why Clickhouse?
- It's just fast
- It's fast because -> "to go faster, do less stuff"
- Columnarity as an advantage
- Clickhouse 101
- Table Creation and Reads
- Parts, Partitions, and Sort Order
- No Primary Keys?
- Indexing?
- Data Skipping Indexes (Bloom Filters)
- But What about Concurrency?
- Clickhouse uses MVCC -> No Locks, non-blocking inserts
- Introducing the MergeTree Engine
- Why is it called MergeTree?
- What's the file structure like?
- Sparse Indices
- Parts
- Marks
- The Basic Principle: merging parts in the background
- Variants -> CollapsingMergeTree, SummingMergeTree
- Why are Writes Fast?
- Writing as parts
- Compression
- Wide and Narrow Layouts
- Mark Files and Sparse Indexing
- Auto-shifting data between HDD and SSD (Multiple Block Devices feature)
- Why are Reads Fast?
- The Primary Key is a superpower
- How the Sparse Index helps eliminate granules (to go faster, do less stuff)
- The Primary Key is a superpower
Approach - Start off with how data is stored, and how that makes things faster - focus more on organization; data structures exist to make lives easier, choosing the right data structure is essential
What is an Engine?
To understand what an Engine is, we must first understand the components of a database.
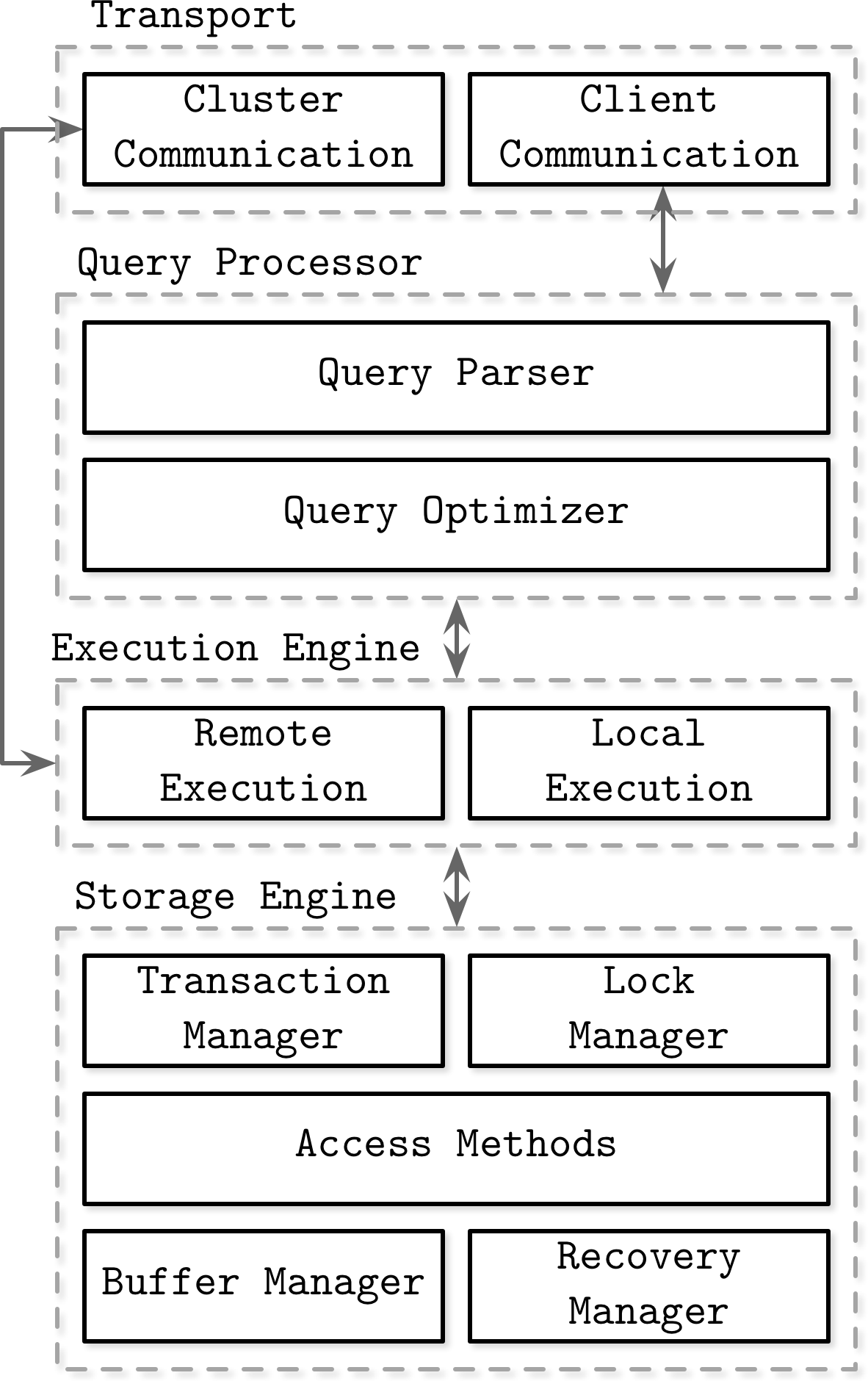

Here, we see that a DBMS is nothing but a lot of layers of abstraction that terminate at the storage level. These abstractions inlcude a query parser, a query processor, a compiler, a planner, and a transaction manager. All of these ultimately work towards ensuring that data that has been stored can be queried and manipulated in the most optimal manner possible.
"The storage engine is the part of the DBMS that's responsible for storing, retrieving and managing data in-memory and on-disk" ~ Alex Petrov, Database Internals
So, given the ultimate dependence of the rest of the database on storage and retrieval, the storage engine sometimes supports or implements other features like transactions to give the DBMS developers fine-grained control of what's going on.
The TL;DR is that the storage engine is what supports storing and retrieving data as efficiently as possible, and the rest of the DBMS is built around it, and using it. A DBMS is useless without a good storage engine.
What is Clickhouse?
ClickHouse® is a high-performance, column-oriented SQL database management system (DBMS) for online analytical processing (OLAP).
Clickhouse is what we use here in prod at Bytebeam.
It's a column-oriented DBMS, which means that data is grouped by column, not by row. Through sheer locality and cache-friendliness, this decision to store data by column and not by row makes a massive difference in performance, especially for analytical usecases where column-wise aggregate statistics (mean, median, mode, min, max) and groupings (group by) are extremely common.
OLAP vs OLTP
When we think of a database, we think of postgres or mysql. Clickhouse is similar, but it's an OLAP database, not an OLTP Database. The scope of problems is different here -
- Dealing with massive datasets -> Billions or Trillions of rows
- The tables have many, many columns
- Of these columns, any query needs only a few columns
- results must be returned in milliseconds or seconds
So, given these constraints, Clickhouse has managed to find a space in which it can make signinficant optimizations with the entire DBMS.
Why is Clickhouse Fast?
To go fast, do less stuff.
Clickhouse makes some pretty impressive claims - "Query a billion rows in milliseconds" is no small matter. There are multiple choices that they took at a design and architecture level to make sure their performance was top-notch, so in reality it is possible for them to query a billion rows in milliseconds.
Let's explore a few of these choices listed here.
What difference does the engine make? Isn't it just a part of the architecture?
So as we've been able to see, the reason clickhouse is able to be so performant is that it has optimizations that reach all the way down to the storage layer and the format. The engine can be considered to be the bottleneck of the entire operation, as it issues the syscalls necessary to persist, fetch, or re-organize data.
You can force Direct I/O (Kernel Page/Buffer Cache Bypass) in Clickhouse with the following
SET min_bytes_to_use_direct_io=1
- clickhouse parallelizes I/O really well. (how?)
- If clickhouse was a car, it would be a drag racer. It doesn't have an optimizer (but somehow has transactional catalogs! Non-ACID Transactions!
Materialized Views can be thought of as synchronous post-insert triggers!! last-point queries in time-series data -> the latest sample of data double-delta encoding for time-series data ~ 99.9% compression ratio
Distributed Joins are not optimized in Clickhouse.
Sharding and replication -> Multi-master, eventually consistent
The MergeTree Engine

- MergeTree Layout consists of indexed chunks of data (every ~8000 or so rows,
sparse index) -> Sorted and Compressed. Sprase index (
primary.idx) -> multiple granules (distance between rows).mrkfile -> maps granules to a compressed segment inside the.binfile
Insert data into table, atomic merge in the background - you can somehow instantly query them? "Instantly query after insert, but optimize over time"
deletes are expensive! you need to rewrite the entire part.
Why should you know?
The more you understand how the engine works, the faster you can drive it.
The execution Model
Key Components:
- Thread
- Hash Table
Table Creation
CREATE TABLE IF NOT EXISTS sdata (
DevId Int32,
Type String,
MDate Date,
MDatetime Datetime,
Value Float64
-- This is the table engine - there are many variants but can only be one per table
) ENGINE = MergeTree()
-- This is how we'll partition the data (break to pieces in a reasonable way)
PARTITION BY toYYYYMM(MDate)
-- This is how we'll index and sort the data (A Clustered Index)
ORDER BY (DevId, MDatetime)
Insert Processing
INSERT INTO sdata VALUES
(15, 'TEMP', '2018-01-01', '2018-01-01 23:29:55', 18.0),
(15, 'TEMP', '2018-01-01', '2018-01-01 23:30:56', 18.7),
Once this is done, data is assembled in memory (post parsing and planning)
- rows pulled in mem
- "part" of the table created, sorted, and index created, too
- once this is done, we store in the file
Basic parallelization to make inserts run faster. Each thread works on one part.
set max_insert_threads = 4
Q: What is a Part?
Storage Structure
A Table consists of multiple Parts A Part consists of a Sparse Index and a set of Columns - Clickhouse uses the primary key as the sort order, same as the clustered index
Section -> 8000~ or so rows in one Granule (Clickhouse is optimized for aggregates, not point lookups)
.mrk -> Mark file, index from primary key to point in compressed .bin file
that may or may not contain multiple granules
MergeTree: Because it merges parts in the background!
- Also known as compaction (see tsdbs)
- Also see: Log-Structured Storage (super, super interesting) and LSM Trees
Bigger parts are more efficient!
PARTITION BYshould give you large partitions- Insert in BULK (~10s of Millions of Rows), keeps merge count low -> Batching is GOOD!
ClickHouse cannot use an index if the values of the primary key in the query parameter range do not represent a monotonic sequence. In this case, ClickHouse uses the full scan method.
For example, the days of the month are partially monotonic sequences.
Sources
- https://www.youtube.com/watch?v=fGG9dApIhDU
- https://www.youtube.com/watch?v=ZOZQCQEtrz8
- https://clickhouse.com/docs/en/intro
- https://clickhouse.com/docs/en/about-us/distinctive-features
- https://clickhouse.com/docs/en/engines/table-engines
- https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree#mergetree
- https://www.youtube.com/watch?v=XpkFEj1rVXg
- https://posthog.com/handbook/engineering/clickhouse/data-storage